Genel Bakış
Bu makalede Python'da BeautiifulSoup kütüphanesine giriş yapacağız. Daha fazla bilgi istiyorsanız BeatifulSoup için oluşturulan resmi dökümana buradan ulaşabilirsiniz.
BeautifulSoup Nedir?
BeautifulSoup, HTML ve XML dosyalarından verileri çekmemiz için oluşturulan bir Python kütüphanesidir.
BeautifulSoup3 yada 4?
BeautifulSoup3, BeautifulSoup4 ile değiştirildi.
BeautifulSoup3 sadece Python2.x sürümlerinde çalışırken BeautifulSoup4 Python3.x sürümlerinde de çalışmaktadır.
BeautifulSoup4 daha hızlıdır, daha çok özellik bulundurur ve lxml, html5lib gibi üçüncü parti yazılmlarla çalışır.
Sende bütün yeni projelerin için BeaifulSoup4 kullanmalsın.
BeatifulSoup Kurulumu
Ubuntu veya Debian ile çalışıyorsanız BeautifulSoup'u sistem paket yöneticisi (system packet manager) ile kurabilirsiniz.
apt-get install python-bs4
Eğer sistem paket yöneticisi ile yükleyemezseniz, Python programlama dili için oluşturulmuş yazılım deposunda (PyPi) bulunduğu için easy_install veya pip komutlarıylada yükleyebilirsiniz.
easy_install beautifulsoup4
yada
pip install beautifulsoup4
Eğer easy_install veya pip ile de indiremezseniz. BeautifulSoup modülünün kaynak kodlarını indirip setup.py dosyasını çalıştırmanız işiniz görecektir.
python setup.py install
BeautifulSoup Kullanımı
Yükleme işleminden sonra BeautifulSoup modülünü kullanmaya başlayabiliriz. İlk olarak BeautifulSoup modülümüzü kullanabilmek için projemize import etmemiz gerekiyor.
Artık soup isminden bir nesne (object) oluşturabilmemiz için bir şeyler yapalım. Bunun için bir belge veya URL'e ihtiyacımız var.
Şunu da bilmek gerekir ki BeautifulSoup bizim için web sayfalarının kaynak kodlarını çekemez. Bunu yapmak için urllib2 modülü işimizi görecek. Bu iki modülü bir arada kullanarak işimizi göreceğiz.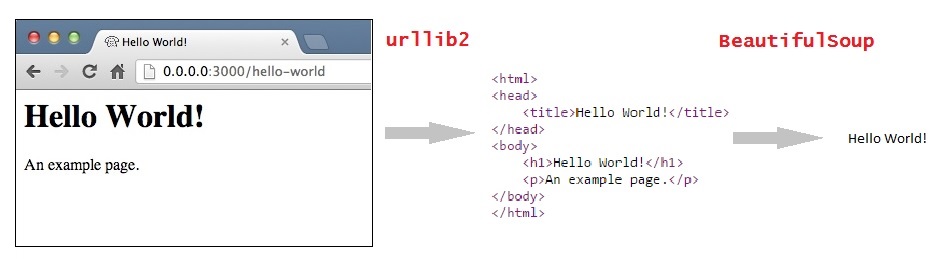
Quick Start
Bu belge örnek olarak kullanacağımız HTML formatında bir belge ve "Alice Harikalar Diyarında" hikayesinden bir alıntı.
html_doc = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
BeautifulSoup ile bu belgeyi çalıştırırsak bize sonuç olarak iç içe geçmiş bir veri yapısı olarak BeautifulSoup nesnesi verir.
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc, 'html.parser')
print(soup.prettify())
# <html>
# <head>
# <title>
# The Dormouse's story
# </title>
# </head>
# <body>
# <p class="title">
# <b>
# The Dormouse's story
# </b>
# </p>
# <p class="story">
# Once upon a time there were three little sisters; and their names were
# <a class="sister" href="http://example.com/elsie" id="link1">
# Elsie
# </a>
# ,
# <a class="sister" href="http://example.com/lacie" id="link2">
# Lacie
# </a>
# and
# <a class="sister" href="http://example.com/tillie" id="link2">
# Tillie
# </a>
# ; and they lived at the bottom of a well.
# </p>
# <p class="story">
# ...
# </p>
# </body>
# </html>
Bu veri yapısını basit yollarla gezelim.
soup.title
# <title>The Dormouse's story</title>
soup.title.name
# u'title'
soup.title.string
# u'The Dormouse's story'
soup.title.parent.name
# u'head'
soup.p
# <p class="title"><b>The Dormouse's story</b></p>
soup.p['class']
# u'title'
soup.a
# <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
soup.find_all('a')
# [<a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>,
# <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>,
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
soup.find(id="link3")
# <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>
Örneğin bütün <a> etiketlerindeki URL'leri ayıklamasını istersek
for link in soup.find_all('a'):
print(link.get('href'))
# http://example.com/elsie
# http://example.com/lacie
# http://example.com/tillie
veya bir sayfadaki HTML dosyasından sadece metin kısımlarını ayıklamasını istersek
print(soup.get_text())
# The Dormouse's story
#
# The Dormouse's story
#
# Once upon a time there were three little sisters; and their names were
# Elsie,
# Lacie and
# Tillie;
# and they lived at the bottom of a well.
#
# ...
soup Nesnesi Oluşturalım
Bir belgeyi parçalamak istiyorsanız onu BeautifulSoup yapısının içine aktarın. Bu aktardığınız belge aşağıda gösterildiği gibi bir string ifade de olabilir dosyanın kendisi de olabilir.
from bs4 import BeautifulSoup
with open("index.html") as fp:
soup = BeautifulSoup(fp)
soup = BeautifulSoup("<html>data</html>")
İlk olarak belge Unicode'a çevrilir. ve HTML içerik Unicode karakterlere çevrilir.
BeautifulSoup("Sacré bleu!")
#<html><head></head><body>Sacré bleu!</body></html>